Stereo Vision & Depth
Seeing in 3D
Hold a finger up at arm's length. Close your left eye, then your right, back and forth. The finger jumps sideways against the wall behind it. Now do the same with a tree across the street: it barely moves at all.
You just measured depth. Not with a tape measure, not with sonar, but with two slightly different views of the same world and a brain that knows how to read the difference between them. Each eye sees from a vantage point a few centimeters from the other, and that tiny offset is enough.
Two views of one scene, plus a little geometry, is all it takes to turn flatness back into depth.
A single photograph is a one-way street. The world has three dimensions, the sensor has two, and the act of projection throws the third one away: every point along a ray from the lens lands on the same pixel, so the camera can never tell which one you meant. The cure is parallax, the apparent shift of a point when you move your viewpoint. Give a system two eyes, separated by a known distance, and the near things shift more than the far things. Measuring that shift, and reasoning backward through the geometry of the two cameras, lets you recover the depth the single image lost. This is stereo vision, and biology and computers solve it the same way.
Drag the baseline slider (how far apart the two cameras sit) and the disparity slider in the sim below, and watch the recovered depth Z respond. Look for the inverse relationship: as the same point's left-right shift grows, the depth it implies shrinks, and vice versa.
What the sim is quietly demonstrating is the single equation that powers all of stereo: depth is not measured directly, it is inferred from how far a point appears to move between the two views. A big jump means close. A whisper of a shift means far. Get the cameras' separation and focal length right, and that shift becomes a ruler.
Disparity is a ruler in disguise
Set up two cameras side by side, looking forward, separated by a baseline . A 3D point in the world projects to a horizontal position in the left image and in the right.
The disparity is simply the difference:
Here is the point's column in the left image, is its column in the right image, and is the horizontal offset between them, measured in pixels. The governing relationship between that offset and the true depth is:
where is the depth (distance from the cameras to the point), is the focal length in pixels, is the baseline (the physical distance between the two camera centers), and is the disparity. The shape of this equation is the whole story: and are inversely proportional. Double the disparity and you halve the depth. A point at infinity has zero disparity (it sits at the same pixel in both views); a point right in front of your nose has enormous disparity. That is exactly the finger-versus-tree experiment, written in symbols.
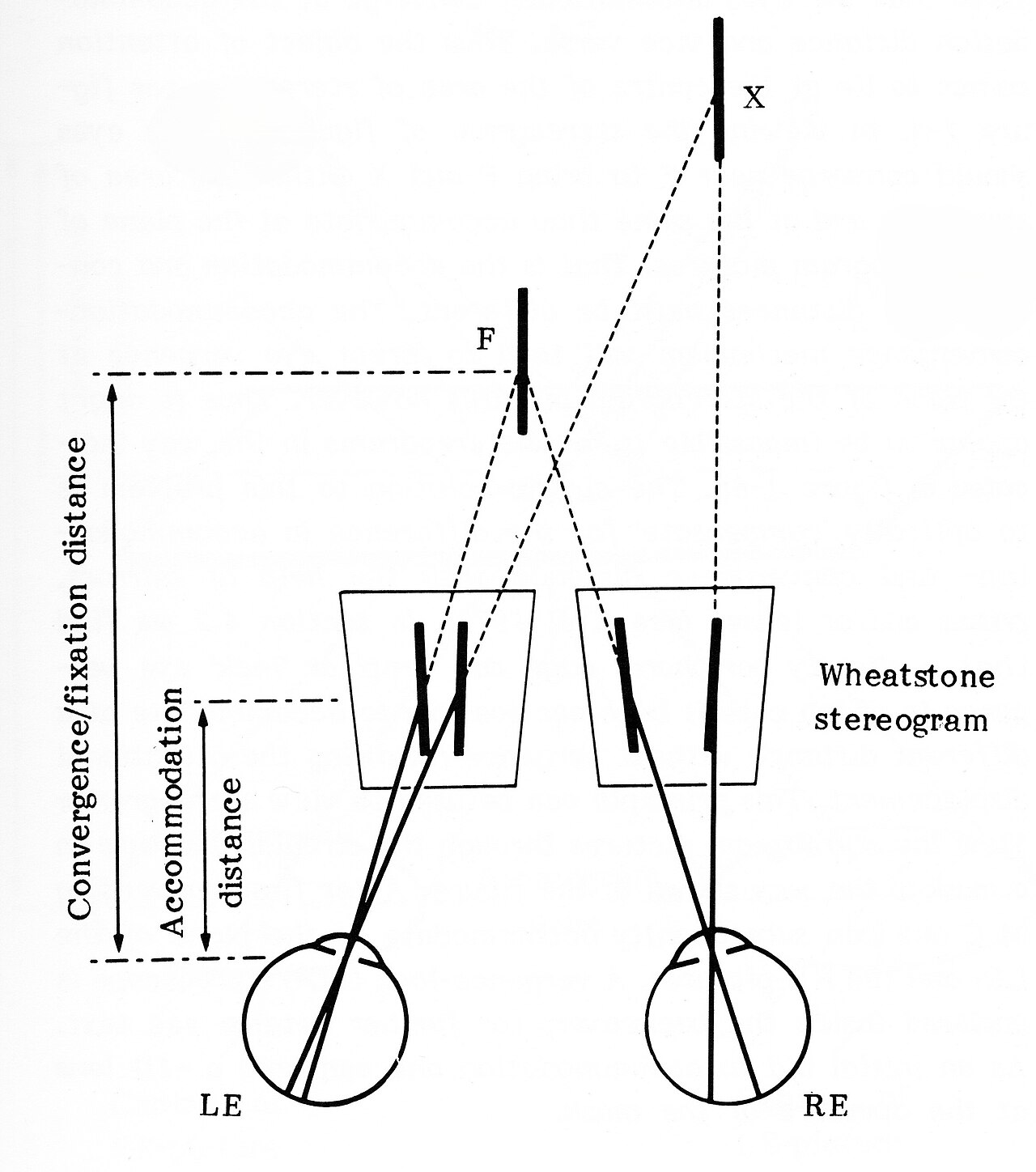
Where disparity comes from: your two eyes
Biology got here first. Your visual system fixates both eyes on a single point, and because the eyes look from slightly different directions, every other point in the scene lands on subtly different spots on the two retinas. That mismatch is binocular disparity, and the brain reads it as depth. The sensation it produces, the felt solidity of the world, has its own name: stereopsis, from the Greek for "solid sight."

Crucially, disparity is not the only depth cue your brain uses. Close one eye and the world does not collapse into a flat sheet: you still read depth from monocular cues like relative size (far things look smaller), occlusion (near things hide far things), linear perspective (parallel lines converge), and texture gradients (texture gets finer with distance). Stereo gives you precise depth up close; the monocular cues carry you the rest of the way out to the horizon.


From two photos to a depth map
For a computer, the geometry above is the easy part. The hard part is correspondence: for each pixel in the left image, which pixel in the right image is the same physical point? Get that wrong and your disparity is garbage. The trick that makes the search tractable is rectification: you warp both images so that corresponding points always land on the same horizontal row. Then matching a pixel is a one-dimensional hunt along a single line instead of a search over the whole frame.
Once images are rectified, the matcher slides a small window along each row and scores how well the patches agree. Block matching does exactly this, fast but noisy. Semi-global matching (SGM) adds a smoothness penalty so neighboring pixels prefer similar depths, killing speckle. Modern systems train convolutional networks on stereo pairs and learn the matching directly. Whatever the method, the output is a disparity map, one disparity value per pixel, which the depth equation converts into a depth map: an image where brightness encodes distance, bright for near and dark for far.
That depth map is the payload. It feeds 3D reconstruction, lets a robot avoid an obstacle, drives the soft background blur of a portrait photo, and tells an AR headset which virtual objects should be hidden behind real ones.
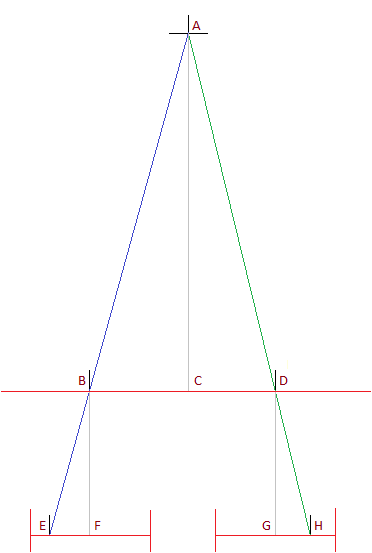
Why Z = fb/d falls straight out of similar triangles
Put the two cameras in a rectified, fronto-parallel rig: optical axes parallel, image planes coplanar, separated by baseline along the -axis, each with focal length . Place the origin at the left camera center. A world point sits at depth and at horizontal offset from the left camera.
By the pinhole projection law, the left image coordinate is the focal length scaled by the angle to the point:
The right camera is shifted by , so it sees the same point at horizontal offset :
Subtract to get the disparity, and the unknown cancels cleanly:
Invert and you have the depth equation in its working form:
Two consequences fall out immediately. First, the precision of depth degrades with the square of distance: differentiating gives , so a one-pixel matching error costs you proportionally far more depth accuracy on distant objects than on near ones. Second, the only knobs you control are and : a longer focal length or a wider baseline both buy you sharper depth, which is exactly why long-range stereo rigs splay their cameras far apart.
Key takeaways
- Depth is inferred, not measured. A camera cannot read distance off a single image; stereo recovers it from how far a point shifts between two views.
- Disparity is inversely proportional to depth: . Big shift means near, tiny shift means far, zero shift means infinitely far away.
- You tune precision with and . A wider baseline or longer focal length sharpens far-distance accuracy, at the cost of bigger occlusion zones.
- Correspondence is the real work. Rectification reduces matching to a 1D search per row; block matching, SGM, and CNNs trade speed for smoothness and accuracy.
- Texture is required. Blank walls, reflections, and occlusions are where stereo produces holes, which is why real systems fuse stereo with monocular and motion cues.
Wheatstone fooled a brain with two drawings and a pair of mirrors, and in doing so revealed that depth was never out there in the world: it was a calculation, run between two slightly disagreeing eyes. Every stereo camera since, from a Mars rover to the lenses on your phone, is running that same calculation. Close one eye, then the other, and watch your finger jump. You are doing geometry, and you have been since before you could count.